When Prompts Become Shells: Unpacking RCE Vulnerabilities in AI Agent Frameworks
When Prompts Become Shells: Unpacking RCE Vulnerabilities in AI Agent Frameworks
Date: 2026-05-08
Discover how subtle prompt injection flaws in AI agent frameworks can lead to remote code execution and learn essential strategies to safeguard your intelligent agents.
Tags: ["Security", "AI", "Remote Code Execution", "Semantic Kernel", "Cybersecurity"]
The rise of AI agent frameworks has revolutionized automation and intelligent assistance, enabling applications that can interpret natural language prompts and perform complex tasks autonomously. Yet, with this new paradigm comes a novel class of security challenges. What if those seemingly innocent prompts could be weaponized to execute arbitrary code on your systems?
Microsoft's recent research into this very threat uncovers how prompt injection in popular AI agent frameworks—particularly those using Semantic Kernel and its In-Memory Vector Store—can escalate into Remote Code Execution (RCE) vulnerabilities. This deep dive exposes the intricate attack chains, representative cases, and practical mitigations that developers and security professionals must understand to defend the agentic edge.
In this post, we’ll explore the architecture of these AI agent frameworks vulnerable to prompt attacks, analyze key technical insights from the Microsoft Security Blog, and provide actionable guidance on securing your AI-driven systems against such exploits.
Architecture Overview
┌────────────────────────────────────────────┐
│Architecture │
├────────────────────────────────────────────┤
│• Enterprise data sources │
│• Foundry platform │
│• AI applications │
└────────────────────────────────────────────┘
Key Technical Observations
-
Prompt Injection as Code Injection Vector — Unlike traditional RCE vulnerabilities exploited via direct user input parameters, these flaws exploit the very mechanism meant to interpret natural language instructions, turning prompts into code shells.
-
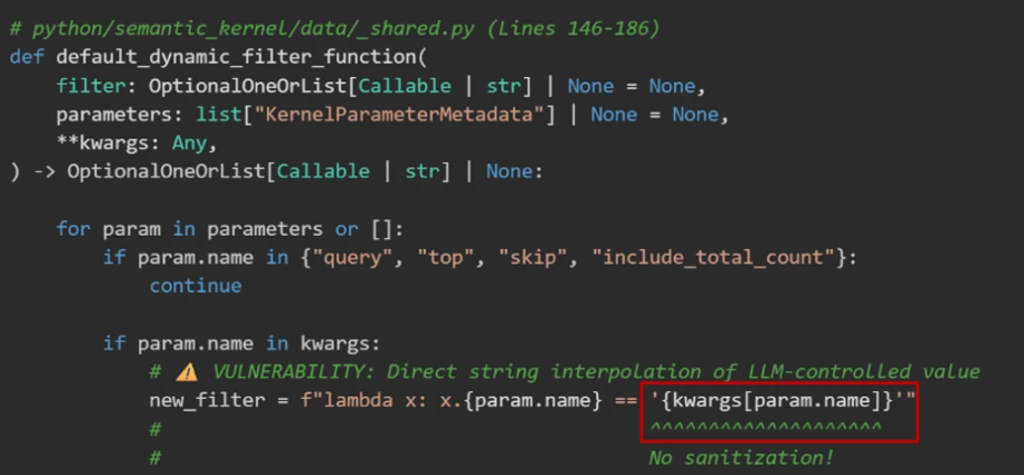
Unsafe String Interpolation in Lambda Filters — The In-Memory Vector Store’s filter functionality interpolates user input into Python lambda expressions without sufficiently strict sanitization, allowing malicious expressions to bypass controls and execute arbitrary code.
-
Ineffective Blocklists Create False Security — The usage of avoidable blocklists scanning for dangerous tokens like
eval,exec, oropenfails to cover all attack vectors, while attackers can craft payloads that evade detection by leveraging allowed constructs. -
AST Node-Type and Attribute Whitelisting — The framework attempts to restrict execution through an AST allowlist and evaluating calls only to safe functions, combined with blocking dangerous attribute lookups (e.g.,
__class__,__subclasses__), but subtle bypasses remain possible. -
Python Sandbox Environment Limitations — Built-in functions like
openandprintare deliberately removed from execution contexts; however, limited escape routes through module import mechanics or system command invocation present significant risk. -
SessionsPythonPlugin Arbitrary File Write — Identified as CVE-2026-25592, this vulnerability allows attackers to write arbitrary files—opening paths for persistence or arbitrary code placement beyond runtime code execution.
How It Works: Dissecting the Attack Chain
Understanding Prompt Injection in AI Agents
AI agent frameworks like Microsoft's Semantic Kernel accept user prompts and transform them into programmable actions by dynamically generating snippets of code—commonly Python lambda expressions—that are evaluated on the fly. When an attacker manipulates the prompt input, they can inject payloads that alter these generated code snippets.
CVE-2026-26030: In-Memory Vector Store Vulnerability
The In-Memory Vector Store’s Search Plugin relies on filtering results via Python lambda expressions constructed with user input. This usage involves:
lambda x: x.city == "<user_input>"
If the input contains malicious code, such as:
' or MALICIOUS_CODE or '
it can corrupt the lambda expression, enabling unexpected evaluation beyond a simple string comparison.
Microsoft’s research found that the framework implements:
- A blocklist filtering suspicious keywords.
- AST-based validation allowing only safe constructs (comparisons, booleans, literals).
- Name node restrictions to allow only the lambda parameter and forbid references to unsafe modules or functions.
Despite these, attackers can craft inputs bypassing these controls, leading to execution of arbitrary code within the agent's runtime environment.
Exploiting Arbitrary File Write via SessionsPythonPlugin
CVE-2026-25592 targets the SessionsPythonPlugin, which mishandles file path validation for session data storage or plugin operations, allowing attackers to write arbitrary files outside intended directories. This compromises system integrity by enabling persistence mechanisms or replacing trusted code.
The Attack Chain Summary
- Prompt Injection Vector: The attacker must find a way to influence an agent’s prompt input.
- Use of vulnerable Search Plugin: The agent utilizes the default configuration of the In-Memory Vector Store with unsafe filtering.
- Payload crafting: The attacker inputs an expression that slips past sanitization.
- Lambda expression corruption: The filter lambda executes malicious code.
- Code execution at runtime: Executes within the Python sandbox, potentially breaking out to OS commands.
- Post-exploitation techniques: Depending on file write vulnerabilities, attackers can plant persistence or further system compromise.
Defenses and Mitigations
Microsoft highlights vital defenses, including:
- Upgrading Semantic Kernel to version 1.39.4 or later with hardened filtering logic.
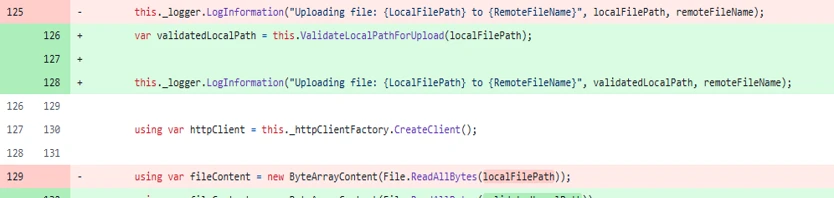
- Adding path validation methods such as
ValidateLocalPathForDownload()to ensure canonical paths and directory allowlists. - Incorporating zero-trust security models restricting agent execution contexts and system access.
- Employing runtime monitoring and detection using behavior-based techniques for suspicious subprocess spawn patterns.
Source: Microsoft Security Blog
Quick Tips & Tricks
-
Upgrade Semantic Kernel Immediately — Always use the latest Semantic Kernel SDK version (≥1.39.4) to benefit from patched input sanitization and improved security controls.
-
Avoid Default Configuration for In-Memory Vector Store Filters — Customize or disable vulnerable search filter functionality that interprets user input as code when possible.
-
Implement Rigorous Path Validation — When plugins or session handlers allow file writes, validate paths with canonicalization and directory allowlists to prevent directory traversal or file overwrite attacks.
-
Enforce Strict Runtime Sandboxing — Limit what built-in functions and imports are available within evaluated code contexts, adding layers of defense against code escaping.
-
Monitor Agent Runtime Behavior — Set up detection rules for suspicious child process creations, unexpected .NET hosting behaviors, or anomalous system command invocations.
-
Practice Adversarial Testing on AI Agents — Use Capture the Flag (CTF) style challenges to probe your AI agents’ prompt injection resistance in controlled environments before production deployment.
Source: Microsoft Security Blog
Conclusion
The convergence of natural language processing and automated agent frameworks is transformative but introduces uncharted security complexities. Microsoft’s research into prompt injection leading to remote code execution underlines how deeply intertwined language interpretation and code evaluation can become a double-edged sword.
Understanding the nuances of unsafe string interpolation, imperfect sanitization mechanisms, and exploitable plugin behaviors is crucial. Developers must treat AI agent input pathways as critical attack surfaces, applying defense-in-depth strategies, continual patching, and vigilant monitoring.
As AI agents proliferate in enterprise and consumer applications, securing the “agentic edge” will require ongoing collaboration between AI engineers, security professionals, and platform maintainers. The evolving threat landscape demands a commitment to resilient design over convenience, ensuring AI can empower without exposing critical infrastructure to compromise.
References
-
When prompts become shells: RCE vulnerabilities in AI agent frameworks | Microsoft Security Blog — Original research article by Microsoft Defender Security Research Team.
-
Semantic Kernel GitHub Repository — Source code and documentation for Semantic Kernel SDK used in the research.
-
Microsoft Defender for AI Security — Tools for runtime protection and detection related to AI agent frameworks.
-
Microsoft Security: Zero Trust for AI Workshop — Guidance on implementing zero trust principles for AI applications.
-
Microsoft Security Blog: Protect your agents in real-time during runtime (Preview) — Additional insights on runtime defenses against AI agent exploits.